- Regular article
- Open access
- Published:
Estimating community feedback effect on topic choice in social media with predictive modeling
EPJ Data Science volume 9, Article number: 25 (2020)
Abstract
Social media users post content on various topics. A defining feature of social media is that other users can provide feedback—called community feedback—to their content in the form of comments, replies, and retweets. We hypothesize that the amount of received feedback influences the choice of topics on which a social media user posts. However, it is challenging to test this hypothesis as user heterogeneity and external confounders complicate measuring the feedback effect. Here, we investigate this hypothesis with a predictive approach based on an interpretable model of an author’s decision to continue the topic of their previous post. We explore the confounding factors, including author’s topic preferences and unobserved external factors such as news and social events, by optimizing the predictive accuracy. This approach enables us to identify which users are susceptible to community feedback. Overall, we find that 33% and 14% of active users in Reddit and Twitter, respectively, are influenced by community feedback. The model suggests that this feedback alters the probability of topic continuation up to 14%, depending on the user and the amount of feedback.
1 Introduction
Social media allow users to post their own content and receive feedback from their audience. Online platforms offer various forms of community feedback, including retweets, comments, replies, up-votes, and down-votes. Social impact theory suggests that a large amount of positive social feedback, such as support from friends, encourages individuals to continue the behavior that triggered the feedback [41]. Social impact theory has been tested by social psychological experiments [42, 43], and there is supporting evidence that social feedback affects consumers’ behavior [56, 59]. These findings are consistent with the seminal operant conditioning experiments showing that animal behaviors are reinforced by rewards [65]. The concern that operant conditioning affects social media users has been raised recently [1, 15]. However, the choice of topic to post is a higher-level cognitive task, in contrast to lower-level behaviors related to survival [50], that has not been studied yet. Thus it is not clear whether the community feedback affects the topic choice or not.
Here we investigate the question of how the community feedback affects a user’s choice of topic to post on social media. This question has practical implications for the design of social media systems. For instance, recommender systems are often designed to optimize for community feedback and engagement. If the feedback affects topics posted by users, then such recommendation algorithms may inadvertently contribute to the growth of polarizing or biased topics that receive more attention than impartial topics [73]. Furthermore, the topics discussed on social media and their evolution are important in modern studies of agenda setting [12, 52].
The following two challenges hinder us from directly measuring the community feedback effect. First, social media users are highly heterogeneous: their profiles range from journalists and organizations with pre-scheduled posting agendas to individuals with private accounts having organic agendas. Distinct kinds of users are likely to process community feedback in very different ways and not all will be influenced by it. To address this heterogeneity issue, we need enough data about the behaviors of individual users over a period of time. The second difficulty lies in measuring and controlling for the external factors that can affect users. For example, users post burst of tweets due to events such as golf tournaments and movie releases [44] as well as debates between political candidates [68]. In this situation, topic changes might be incorrectly attributed to social feedback, rather than the external events that truly influenced users to switch their posts’ topic.
Community feedback received considerable research attention in the following two areas. First, previous studies showed that positive social feedback to online content tends to improve consumer’s opinion about that content [26, 55] and increase their willingness to disseminate it to friends [26]. Our study hypothesizes that this community feedback impacts not only the perception of content consumers, but also the author’s choice to post related pieces of content in the future. Second, analyses of large online communities suggest that positive feedback increases both user retention and the quality of their future posts [9], as well as their activity [14, 16]. Complementing these studies, this research is the first work, to the best of our knowledge, to examine whether community feedback influences the topic choices of social media users.
1.1 Present work
We hypothesize that the amount of community feedback influences an author’s decision to change or continue a topic in their consecutive posts on social media. To examine this hypothesis, we develop a semiparametric model of topic continuation and explore which factors influence the probability of topic continuation (Fig. 1). In this model, we incorporate an unobservable confounding factor—the global topic trend—that can potentially affect the estimate of the community feedback effect. Model-based studies are vulnerable to model misspecification, which may lead to a biased estimate. To address this potential issue, we draw inspiration from philosophy of science by seeking to discover model structure based on its predictive accuracy [17]. To this end, we model the topic trend as a flexible time series and learn it directly from data. To further diminish the risk of model misspecification and examine how other factors affect topic choice, we test various structures of the model components, i.e., community feedback and author properties, by optimizing the prediction accuracy.

Topic trend might be confounders for measuring the community feedback effect on individual users. Activities of two users are depicted: User A changed the post topic due to the global topic trend caused by an external factor (Election); User B changed the post topic due to feedback (Decrease in the number of retweets). This demonstrates the need to control for the topic trend as confounders. In this study, we develop a predictive model that distinguishes the topic trend from the feedback effect
In this way, we identify two essential factors for topic change—author’s topic preferences and global topic trends—and demonstrate that our model achieves high predictive accuracy (82%) for datasets from two social media platforms (Reddit and Twitter). We then use this predictive model to quantify how community feedback affects individual users. While it does not significantly affect most users (67% for Reddit and 85% for Twitter), most affected users exhibit a positive rather than negative effect: users tend to continue with the same topic if they receive a significant amount of feedback.
The contributions of this paper are summarized as follows: we
-
develop a predictive model of author’s topic continuation,
-
identify key factors for the topic change, including external confounders that are hard to measure, and
-
evaluate how community feedback affects individual users in Reddit and Twitter.
The remainder of this paper is organized as follows: Sect. 2 surveys the related works, Sect. 3 describes the datasets from Reddit and Twitter, and Sect. 4 describes our predictive model for authors’ topic changes. In Sect. 5, we examine whether the proposed method can accurately estimate the feedback effect by using synthetic data. In Sect. 6, we demonstrate that this model can extract the topic trends and quantify the community feedback effect and individual authors’ susceptibility to the feedback. In Sect. 7, we discuss our conclusions and expand on the relation between our results and existing works.
2 Related works
2.1 Descriptive studies of feedback in social media
Whereas our work seeks to quantitatively model the role of social feedback for one particular type of behavior, specifically topic choice, there is rich and insightful body of work that studies user’s expectations concerning social feedback [18, 28, 63]. This line of work uses surveys to ask users: (i) about their expectations concerning who is likely engage with their content on social media, and (ii) how they feel when these expectations are (not) fulfilled. Researchers report both a positive feeling of connectedness if feedback is received, and a feeling of disappointment when expectations are not met. Importantly, not only the feedback quantity but also who provides feedback is part of these expectations and affect the resulting feelings. Somewhat related is the observational study by Grinberg et al. [27] who examined the activity change before and after posting on Facebook. They hypothesize that the observed increase in activity level after posting may be partly due to “anticipation of new interactions”.
Research on the “imagined audience” [46] expands on the angle of whom a user expects to read and react to a particular social media post. Through surveys, Marwick and Boyd [49] studied the techniques used by participants to manage things such as different target audiences on Twitter, with different pieces of content intended to reach different audiences. Empirical work by Bernstein et al. [4] studied the imagined audience by combining large-scale log data on the actual readership and engagement with surveys on a user’s expectation. They showed that users tend to dramatically underestimate the actual reach of their content and that public signals such as comment or like counts do not strongly indicate audience size.
2.2 Measuring social influence in social media
Concerning the measurement of social influence in social media there are two main approaches. The first approach is based on experiments, e.g., A/B testing, where users are randomly allocated into treated and untreated groups and the treatment effect is evaluated by comparing the two groups. Lab experiments can control some, but not all, external factors (e.g., controlling for global events would require isolating individuals for long time), and face the issue of external validity, compared to field experiments. Individual effects can be measured if multiple samples are taken from each individual, which may be intrusive to users. Thus, well-controlled experiments are not always tractable owing to such practical and ethical limitations. Due to these difficulties, few experimental studies have been conducted in social media analysis [2, 26, 39]. Two experimental studies that examined the effect of social feedback showed a herding effect of prior positive feedback for social news [55], and higher peer feedback increases the activity for the receiving user [16].
The second approach is based on the observational data without any intervention. A standard framework for controlling variables is the matching methods [60, 67], which have been widely used in social media analysis [9, 14, 34] and has been applied to textual data [57]. This approach has two steps: (i) defining the treated and untreated groups from the data, and (ii) controlling the variables that might influence the outcome. Although the matching methods are powerful when controlling for multiple external variables, defining the treated and untreated groups in observational data is not always clear. For instance, in our study, the treatment variable is the amount of community feedback, which generally is not binary. In such circumstances, more sophisticated propensity score matching can be used to estimate the dose-response relationship [30, 33]. However, matching without additional modeling components does not account for unobserved confounders, which are present in our context in the form of events happening outside of social media, potentially skewing authored topics to the topics of these events.
In this study, we utilize a regression model with a hidden variable to identify the effect of community feedback on user’s choice to continue a topic from observational data. Our approach is similar to the structural equation model (SEM) for causal inference [31, 64, 66] in the sense that both approaches assume a regression model between the cause and the effect. There are mainly two differences between SEM and the proposed method. First, whereas the SEM aims to discover the causal direction from the data, the proposed method does not identify it. We know the direction of the cause and effect, because a potential cause should occur before the effect, and the social feedback was accumulated before the topic choice, so the feedback might cause topic continuation, but not vice versa. Second, the proposed method is more flexible than traditional SEMs, because we do not specify the functional form of the time series of topical trends. Instead, we learn it directly from data based on a weak specification, which is related to semiparametric approaches to causal inference [5, 31]. Advantages of the proposed method are as follows: (i) it does not require researchers to define the treatment and control group, simplifying the estimation of individual effects, (ii) it is straightforward to incorporate a continuous treatment variable, and (iii) it allows researchers to model unobserved confounders that impact multiple individuals. However, predictive models may give biased results if they are misspecified. For this reason, various definitions of each model component need to be tested and their structure must be selected based on their predictive accuracy on a hold-out test data or a model selection criterion [22]. We will discuss this limitation in detail in Discussion.
2.3 User modeling in social media
In this study, we develop a model of user behavior that predicts an author’s topic continuation on social media. Related research endeavors pertaining to social media introduced user behavior models predicting retweeting behavior [71, 74] and post topics [70, 72]. The user behavior model we develop is similar to the one proposed by Xu et al. [70] in the sense that both models incorporate the effect of user interests and exogenous factors. All previous studies have focused on improving either prediction accuracy or recommendation performance. Conversely, our investigation uses an interpretable predictive user model to understand the treatment effect of community feedback. Furthermore, this is the first study to focus on topic changes in user posts on social media.
The author behavior model developed in this study is motivated by the concepts of endogenous and exogenous factors in the activity on the Web and social media. Endogenous factors are defined as interactions within social media or social networks, while exogenous factors are external influences on a community, such as news, catastrophes, and social events, which typically happen externally to social media. Previous studies have suggested that these factors can affect the shape of peaks in popularity profiles such as in search queries on Google, viewing activity on YouTube [13], and the adoption of hashtags on Twitter [19, 44]. We develop a predictive model incorporating topic trends as exogenous factors and a method for estimating these factors from observational social media data.
3 Dataset
We investigate the effect of community feedback on the users’ posting behavior based on two popular online discussion platforms: Reddit and Twitter. We collected the posts created by thousands of active users: so-called submissions in Reddit and tweets in Twitter. Then, for each of these posts, we gathered the community feedback in the form of comments in Reddit and retweets in Twitter. While there are other kinds of feedback available in these platforms, such as up/down-votes or likes (which we study in Appendix A), we focus on these two feedback types, because only for them we are able to collect the time stamps of their creation. Having these timestamps is required for estimating the community feedback at the moment when the author creates their next post, because this feedback can causally influence topic choice. We gathered this data for the period of six months, between January 1–June 30, 2016. Table 1 summarizes the statistics of these datasets.
3.1 Reddit
Reddit Footnote 1 is a social news and discussion website. Users can submit pieces of news or content (e.g., links, videos, and texts) and can vote and comment on these submissions. The submissions are organized by categories, called subreddits, which cover a variety of topics, ranging from politics and science to sports and entertainment. Each user can subscribe to, post in, and comment in multiple such subreddits. In our predictive model, we treat each subreddit as a different topic and model the probability that a user continues to post within the same subreddit.
We downloaded submissions and comments from 100 active subreddits using the Reddit data shared by pushshift.io.Footnote 2 Previously identified gaps in this data [20] do not apply to our collection because the pushshift.io data had been updated since the gaps were pointed out. The active subreddits were extracted according to the following procedure. After extracting the top 1000 subreddits with the highest number of subscribers, we selected the top 100 subreddits receiving the most comments and removed inactive users who posted less than 50 posts in the six month. In addition, we estimated the fraction of positive, neutral, and negative comments in these subreddits, using a sentiment analysis tool for social media texts [32]. We found that positive comments, which may have positive effect on topic continuation, are more common than other comments.
3.2 Twitter
Using Twitter’s streaming API, we collected tweets posted by experts and their retweets. According to previous works [23, 25], an expert is defined as a user satisfying four criteria: (i) they have less than one million followers, (ii) they receive at least 10 retweets per tweet, (iii) they have posted at least 50 tweets during the 6 months, and (iv) they tweet predominantly in English (at least 95% of tweets in English). Most of these users are estimated to be humans (72%), as opposed to organization accounts, by Humanizr tool [53]. These expert users are also less likely to be bots, since they tend to be verified accounts that are in multiple Twitter lists [23]. We first downloaded the tweets posted by experts, and the retweets were crawled a few months after the tweets were posted. The tweets whose retweets could not be crawled were excluded from our analysis. Tweets have a limited number of characters, so users who want to publish a longer post are forced to represent it as multiple tweets posted in a quick succession, what is known as a tweet thread. To remove such threads, we discarded a tweet if the consecutive post is published within less than 30 seconds. Then, again, we removed inactive users who posted less than 50 tweets.
For each original tweet authored by experts, we identified its topic, using a topic model. We first filtered out the retweets and replies and removed URLs and stop-words from the original posts. Then, we obtained a topic for each tweet by using Twitter-LDA [75], with the number of topics K set to 100, unless stated otherwise. Our explorations suggest that our results are qualitatively not affected by the choice of K (Appendix B).
4 Modeling author behavior
Our study attempts to quantify to what extent each author is susceptible to the community feedback by using a predictive model. Here, we describe the model, its components, and the procedure for fitting model parameters.
4.1 Model for predicting topic continuation
We focus on predicting whether an author continues to post on the same topic or not. Modeling the phenomenon of topic change, instead of topic selection, reduces the number of samples required to learn model parameters. The probability that an author i continues a topic k at time t is described as
where \(Y_{i}\) is a binary random variable representing whether the author continues the topic (1) or not (0), f is the community feedback that the user received to their previous post, and \(S(x)\) is a logistic function. In other words, we asssume that the relation between the explanatory variables (\(u_{i}\), g, and f) and the probability of topic continuation is a logistic function. We adopted the logistic function, because results of randomized experiments on social influence suggest this parametric family [3, 26] and prior works show that it can be derived as a model of decision-making under social influence, by comparing judgements under uncertainty to Bayesian inference [3]. In addition, the logistic regression model allows us to incorporate the impact of hidden dynamic confounders, i.e., the topic trends. Importantly, the causal effect is identifiable under this model, because the objective function (Eq. (2)) is concave and model parameters are uniquely identified by its global minimum [7]. By contrast, deep neural networks could achieve a better prediction performance, but these models often have multiple local minima [10], which results in problems with identifiability. In addition, the interpretability of such models is limited—it is a subject of ongoing research and active debate [45]. Other black-box machine learning methods, such as random forests, face the identifiability and interpretability issues as well, and are a subject of active research [69].
Next, we explain each of the three components of this model. The first component \(u_{i}(k; a_{i}, b)\) represents the effect of author properties, where \(a_{i}\) is the user’s propensity to continue any topic and b is the effect of the topic preference on the probability of topic continuation. We will determine a specific form of user properties by optimizing the model accuracy (Sect. 6). The second component \(g(k, t)\) is the effect of the topic trend defined as a flexible time series. Finally, \(\alpha _{i}\) represents author’s susceptibility to the community feedback f. The feedback f is a function of the number of comments or up/down-votes (Reddit), retweets or likes (Twitter) to author’s previous post. Again, we will determine a specific form of the feedback function by optimizing the model accuracy (Sect. 6).
The central assumption allowing the proposed model to infer the multidimensional missing confounder, i.e., the topic trends, is that all users are affected by this confounder in the same way. We show that our model accurately infers such missing confounders by using a synthetic data (Sect. 5).
4.2 Parameter inference
We describe the procedure to specify the model structure and to estimate the parameters. For tractability, the topic trend \(g(k, t)\) is approximated by a step function with one time interval per day.Footnote 3 This step function is represented by the vectors \(\vec{g}_{k}= \{ g_{k, 1}, g_{k, 2}, \ldots, g_{k, M} \}\), where k represents a topic, and \(M= 182\) is the number of time intervals, i.e. days in our data. In addition, the trend is assumed to be a smooth function of time t, which is enforced by L2 regularization [35, 36, 38].
Overall, we estimate \(KM+ 2N+ 1\) parameters (approximately 32,300 and 32,000 parameters for Reddit and Twitter, respectively): \(\{ \vec{g}_{1}, \ldots, \vec{g}_{K}, \vec{a}, b, \vec{\alpha } \}\), where K is the number of topics, and N is the number of users, \(\vec{a} = (a_{1}, \ldots, a_{N})\) is a vector of authors’ propensities, and \(\vec{\alpha }= (\alpha _{1}, \ldots, \alpha _{N})\) is the susceptibility of each author to the feedback. The parameters are estimated by maximizing the log likelihood with regularization:
where \(y_{i, j}\) represents whether the author continues the topic (1) or not (0) in the jth sample, and \(\beta _{u}\) and \(\beta _{g}\) are hyper-parameters controlling the strength of L1 regularization of \(a_{i}\) and b [6], and L2 regularization of \(\vec{g}_{k}\), respectively. The first term is the log-likelihood for all users, and j is the subscript for respective time window. We learn the hyper-parameters \(\beta _{u}= 0.1\) and \(\beta _{g}= 10\) via a grid search. The source code for parameter estimation is available on Github.Footnote 4
4.3 Evaluation of prediction accuracy
The prediction accuracy is evaluated on a hold-out set of samples, i.e., the last three posts for each user. The training data is resampled from the remaining data using bootstrapping. The mean and confidence intervals of accuracy are calculated by repeating this procedure 200 times, each time using a different training dataset.
5 Validation on synthetic data
We examine whether the proposed method (Sect. 4) is able to infer the true susceptibility and topic trend by using a synthetic data.
The synthetic data was generated as follows. We first extracted active users who posted more than 50 tweets in the period of 10 days (from 1st, Jan., 2016 to 10th, Jan., 2016) together with the timestamps of their posts, which resulted in 1145 users. Second, we assigned a topic to each post based on the topic continuation model (Eq. (1)). We assumed that the number of topics is two, \(K=2\), and the first post of each user is assigned as a random topic with the probability 0.5. Topics of the subsequent posts are determined by the previous topic and the probability of topic continuation (Eq. (1)). Third, we specify the model structure, i.e., the user property, the topic trend, and the feedback. For simplicity, we assume that the user property is zero, \(u_{i}(k; a_{i}, b)= 0\), and there are two unobserved events at time \(t_{1}=\) 3rd, Jan. and \(t_{2}= \) 7th, Jan., which impact on the topic trend (Fig. 2). The effect of an event on the trends are described as the exponential function, that is, \(g_{k}(t)= g_{0} e^{-(t-t_{k})/\tau }\) for \(t>t_{k}\) and \(g_{k}(t)=0\) for \(t\leq t_{k}\) (\(k=1, 2\)), where \(g_{0}=5\) is the amplitude and \(\tau =4\) [days] is the time scale of the user’s attention. The feedback f is given by a linear function of the trend: \(f= c g_{k}(t)+ \xi \), where k is the topic of the previous post, and ξ is an independent Gaussian variable of zero mean and unit standard deviation. The coefficient c controls the correlation between the feedback and the topic trend. If \(c > 0\) (\(c < 0\)), then the feedback is positively (negatively) correlated with the trend.

Estimating topic trends from synthetic data. Gray lines show the ground truth and the magenta and cyan circles show our estimate. Times of unobserved events are indicated by arrows
Susceptible users are identified based on the proposed model (Eq. (1)) and the naive logistic regression, i.e., the proposed model without \(g(k,t)\). First, we estimate the susceptibility \(\alpha _{i}\) of each user for 200 times by repeating the cross-validation procedure. Second, the user susceptibility is determined to be positive (negative) when the lower (higher) bound of 99% confidence interval of the susceptibility is higher (lower) than zero. The susceptibility is considered to be insignificant if the confidence interval includes zero. The model performance is evaluated by the ability to detect susceptible users. All users were randomly divided into two equal groups. The susceptibility \(\alpha _{i}\) of a user is set to 1 when they belong to a group, and it is set to 0 when they belong to the other group.
We examine two cases: (i) the topic trend is a confounder: \(c= 1\), and (ii) it is not a confounder: \(c= 0\). The naive logistic regression fails to detect the susceptible users if the topic trend is a confounder (Table 2), and most users (99%) are estimated as significantly susceptible. In contract, the proposed method can correctly identify the susceptible users for both cases (Tables 2 and 3). Finally, we show that the proposed model identifies the unobserved confounding events for both topics (Fig. 2), which is the reason why it correctly identifies the susceptible users.
6 Results from social media data
We investigate the community feedback effect on the authors on Reddit and Twitter. The probability of topic continuation calculated from all the posts is 68% on Reddit and 46% on Twitter. We develop the predictive model for the topic continuation, i.e., we determine the structure and values of the author properties \(u_{i}(k; a_{i}, b)\), topic trend \(g(k,t)\), and community feedback, f, by optimizing the predictive accuracy on a hold-out test set. Finally, we exploit this predictive model to evaluate the community feedback effect on individual authors. We investigate author’s susceptibility to the feedback, and the effect of the feedback on the prediction accuracy and the probability of topic continuation.
6.1 Modeling author properties and topic trend
We consider two kinds of author i’s properties: (i) the propensity to continue any topic, \(a_{i}\), and (ii) the effect of the topic preference, b. These properties are included in the model as \(u_{i}(k; a_{i}, b)= a_{i} + b x_{i}(k)\), where \(x_{i}(k)\) represents the preference of a topic k by a user i. The propensity captures a tendency of a user to repeat any topic, e.g., users posting in bursts are more likely to continue a topic, because of their bursty activity. The topic preference captures the bias in posted topics by a user. The probability of posting a topic k for a user i was estimated by add-one Laplace smoothing [61]: \(P_{i}(k) = \frac{N_{i}(k)+1}{N_{i}+K}\), where \(N_{i}(k)\) and \(N_{i}\) are the number of posts on topic k and that of all the posts by the user, respectively. The topic preference is included in the model as \(x_{i}(k) = S^{-1}(P_{i}(k) )\), to ensure that the probability of repeating a topic is equal to the null model of posting based on the topic probability \(P_{i}(k)\), if the other factors are not present, i.e., \(a_{i}=0\), \(b=1\), \(g_{k,j}=0\), and \(\alpha _{i}=0\).
Next, we examine the performance of the models with the various features in predicting whether an author continues to post on the same topic or not (Table 4). Here, we evaluate the predictive performance using accuracy, i.e., the fraction of correct predictions among all predictions measured on the test set. The topic preference, b, largely increases the predictive accuracy by 16% and 15% for Reddit and Twitter, respectively. The propensity to topic continuation, \(a_{i}\), is less important feature than the topic preference, which increases the accuracy by 0.4% and 6% for Reddit and Twitter, respectively. We tested other definitions of both \(P_{i}(k)\) and \(x_{i}(k)\), but this definition resulted in the best predictive accuracy. Overall, these author properties explain 80% of authors’ decisions to continue a topic. The inclusion of topic trend into the model significantly increases the accuracy by 3.0% and 1.5% for Reddit and Twitter, respectively (t-test: \(p < 10^{-20}\)). The effect size (Cohen’s d) was 17.9 and 17.1 for Reddit and Twitter, respectively, which indicates that the effect of the topic trend is huge [11]. In addition to this, we evaluate the prediction performance using the F1 score and the Matthews correlation coefficient [36, 51] (Appendix C). The result is qualitatively the same as that based on the accuracy (compare Table 7 and 7 in Appendix C with Table 4).
Figure 3 shows three examples of the topic trend extracted from Reddit and Twitter dataset. We define the significant period of topic trend as a period of at least three days in which the topic trend is significantly larger than zero. Interestingly, most of the peaks can be interpreted as popular events and news:
-
Sports (Fig. 3(A)): The trend for the subreddit about “nba” increases around the time of NBA players’ trade deadline and the NBA Finals. The Twitter topic trend related to the NFL increases during the NFL season and the Super Bowl championship game.
Figure 3 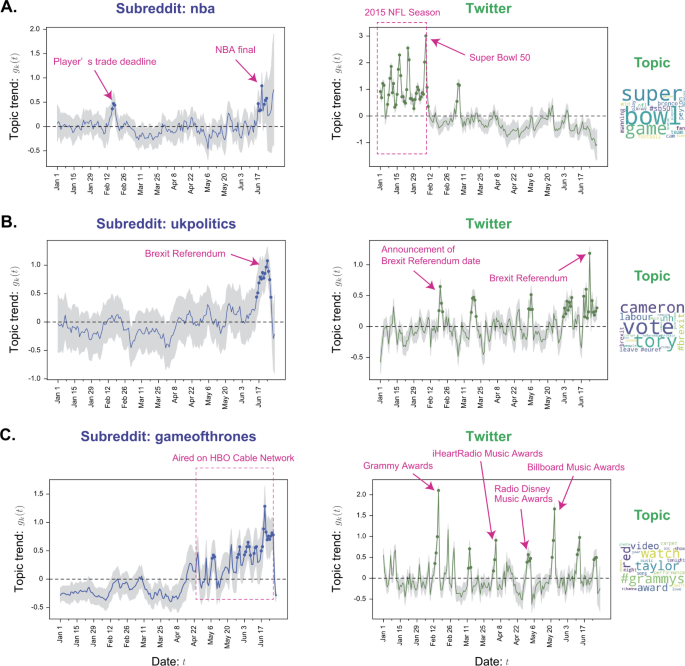
Our predictive model can extract the topic trends which are related to news and social events. Topic trend extracted from three topic categories ((A) Sports, (B) Politics, and (C) Entertainment) are shown. The blue and green lines represent the mean topic trend of Reddit and Twitter, respectively, and the gray area represents the 95% confidence interval. Filled circles mark the days when the topic trend estimate is significantly higher than zero for at least three consecutive days. Social events manually identified from Wikipedia are written in magenta
-
Politics (Fig. 3(B)): The trend for “ukpolitics” subreddit and the corresponding trend of Twitter topic about politics in the UK exhibit a large peak around the time of the Brexit referendum.
-
Entertainment (Fig. 3(C)): The trend for “gameofthrones” subreddit (an American fantasy drama television series) dramatically increases during the period when the drama was aired on HBO cable network. The trend of Twitter topic about music and entertainment exhibit peaks before and after famous music awards, e.g, Grammy Awards.

While most of the peaks in the topic trend are interpretable, there exist multiple peaks that we were unable to interpret (e.g., three middle peaks in Fig. 3(B) for Twitter), either because we lack the knowledge to interpret them or they correspond to the effects present only in some specific groups of users. Finally, we note that the estimated topic trend differs from the time series of the topic popularity, although the two are correlated (Appendix D). The differences have two origins: (i) the topic trend incorporates, in addition to its popularity, the information about topic’s impact on user’s decision to continue posting about the topic and (ii) the topic trend is smoother by design, to maintain model compactness and avoid overfitting.
6.2 Quantifying community feedback
We consider the community feedback as a function of the amount of feedback \(n_{i}\), i.e., the number of comments in Reddit and retweets in Twitter that a user i receives for their previous post. In addition, we also evaluate the feedback based on up/down-votes in Reddit and likes in Twitter (Appendix A). We take into account the following two observations to define the feedback function. First, the amount of feedback depends on the duration Δt from the previous post. The longer the duration is, the more feedback the author will receive. Second, previous works showed that a user’s feeling is associated with the feedback amount relative to their expectations [18, 28, 63].
We consider three functions of community feedback: (i) the feedback rate, \(r_{i}= n_{i}/\Delta t\), where \(n_{i}\) is the feedback amount and Δt is the duration from the previous post, (ii) the logarithm of the feedback rate, \(\log (r_{i})\), and (iii) the cumulative probability of the feedback rate, \(P( R_{i}< r_{i})\), where \(P(R_{i} < r_{i})\) is the probability of receiving feedback smaller than \(r_{i}\) for the ith user. We also consider the feedback functions based on the feedback amount \(n_{i}\), in place of the feedback rate \(r_{i}\); however, it does not improve the predictive performance (Appendix E). In the remainder, we adopt the cumulative probability, \(P( R_{i}< r_{i})\), as the feedback function, because it achieved the best prediction accuracy among these candidates. The addition of community feedback to the model improves the predictive accuracy by 0.14% for Reddit and 0.1% Twitter (Tables 9 and 10 in Appendix E), so this effect is many times smaller in comparison to the effect of author properties and topic trend. Note that this feedback function is a percentile computed with respect to all posts of a user, so it takes into account user’s expectations.
6.3 Susceptibility to community feedback
Next, we evaluate the effect of community feedback on topic continuation separately for each author, by analysing the susceptibility \(\alpha _{i}\) (Eq. (1)). Same as for the synthetic data analysis (Sect. 5), the susceptibility of a user is considered to be positive (negative) when the lower (higher) bound of 99% confidence interval of the susceptibility \(\alpha _{i}\) is higher (lower) than zero. Table 5 shows the distribution of users with positive and negative susceptibility in Reddit and Twitter. First, the community feedback does not significantly affect most users (about 67% and 85% in Reddit and Twitter, respectively). Second, there are few users who are influenced negatively: only 0.2% and 1% of users in Reddit and Twitter, respectively. The corresponding analysis based on the number of up/down-votes on Reddit and the number of likes on Twitter gives quantitatively similar results as Table 5 (Appendix A). As a sanity check, we measure whether including community feedback in the model improves predictive accuracy for the positive users, finding that it improves it by 0.19 ± 0.05% for Reddit and 0.53 ± 0.09% for Twitter. This result does not hold for users with insignificant susceptibility.
Finally, we evaluate the effect of the community feedback based on the probability gain of topic continuation due to reception of an extreme amount of feedback, for each user i:
where \(N_{i}\) is the number of comments or tweets posted by the user, and \(P[Y_{i,j}=1|f]\) is the probability of continuing the topic of the jth post, while the feedback is fixed via an intervention to f [58]. The probability gain is averaged over user’s posts, which estimates the expected increase in the probability of topic continuation due to reception of an extreme amount of feedback (99% percentile), in comparison to medium feedback (50% percentile). Figure 4 shows the distribution of the probability gain for the positive users. The community feedback alters slightly the probability of topic continuation: the median of the probability gain was 2% (6%) in Reddit (Twitter). Finally, we calculate the effect size (Cohen’s d) of the extreme \((f= 0.99)\) and median \((f=0.5)\) feedback. The effect size is 0.18 for Reddit and 0.29 for Twitter, indicating a small effect [11].

Gain of the topic repeat probability due to the community feedback \(\Delta p_{i}\) for the positive users
7 Discussion
We investigate how community feedback affects individual users based on a predictive model. First, we have developed a model that predicts topic changes of an author by incorporating essential features: (i) author’s properties, (ii) global topic trends due to news and social events, and (iii) the received feedback. Our model achieves high accuracy (≈ 82%) for two datasets from social media platforms (i.e., Reddit and Twitter). Then, we quantify the feedback effect on each user level using the model. While this effect does not significantly influence most users (67% in Reddit and 85% in Twitter), it affects the remaining users positively rather than negatively, i.e., these users are more inclined to continue the same topic if they receive positive feedback.
The effect of social feedback varies across different groups of users and social media platforms. The percentage of susceptible users is higher on Reddit than on Twitter, but the effect size is larger for the Twitter users than the Reddit users. We note also that in Reddit the percentage of susceptible users decreases with user activity, whereas it increases with user activity on Twitter (Tables 11 and 12 in Appendix F, respectively). Expert Twitter accounts often belong to celebrities or organizations, who may make use of social feedback in choosing their next topics to maximise engagement. This is not the case in Reddit, where user accounts have significantly lower visibility and organizations and celebrities do not have official accounts, hence there are less incentives for optimizing posting activity for engagement. Future studies can test these hypotheses by distinguishing between different kinds of users (e.g., celebrities, organisations, casual users) in a given social media platform. Here we focused on highly active users (> 50 posts in six months) — the results might be different for less active users. Measuring the effect of community feedback for inactive users is more challenging, because they post less frequently. If users are extremely inactive but post in bursts, as it is often the case [44, 68], the effect of community feedback can be captured by grouping similar users to obtain sufficient numbers of samples per each group.
At first glance the percentage of users susceptible to community feedback might appear to be small. However, Cheng et al. [9] also report “that negative feedback leads to significant behavioral changes that are detrimental to the community. [...] In contrast, positive feedback does not carry similar effects, and neither encourages rewarded authors to write more, nor improves the quality of their posts.” While that study focused on other behavioral changes, repeating our setup while focusing on negative feedback is a future direction to explore. Another reason that the percentage of susceptible users is small could be due to users getting accustomed to feedback and hence starting to “price it in” through certain expectations. For example, Cunha et al. [14] observe “diminishing returns and social feedback on later posts is less important than for the first post.” Though it is theoretically possible to look at changes in susceptibility over time, there are technical limitations related to obtaining complete user timelines. Still, differentiating between “fresh” and “experienced” users could be worth pursuing.
7.1 Limitations
This study has the following limitations. First, we focused on the number of comments (Reddit) and retweets (Twitter), but we did not consider the content or sentiment of the feedback. However, as discussed above, the effect of receiving negative feedback can be quite different from that of positive feedback [8]. While retweets typically imply positive feedback, such as support for the author and agreement with the tweet contents [21, 54], comments and replies often contain a mixture or support and criticism [21]. In our dataset, the positive, neutral, and negative comments accounted for about 40%, 30%, and 30% for the total comments, respectively. This difference in sentiment is a possible reason why the effect of community feedback is smaller in Reddit than in Twitter. It would be interesting to extend the logistic model to incorporate the sentiment of the comments. At the same time, a negative sentiment does not necessarily indicate an antagonistic position towards the original post. For example, a post about a tragic event is likely to attract many comments with a negative sentiment, while agreeing with the original position. Stance detection [40] could hence be a useful direction to explore in the future.
Second, topic classification from short texts (e.g., tweet) is still a challenging task. While most of subreddit titles were interpretable for us, some topics extracted from tweets were not. This might be another reason why the results of Reddit and Twitter are different quantitatively (Tables 5). Note that noise in the topic classifier would lead to an underestimate of the effect that community feedback, or any other feature, has on topic continuation as the dependent variable, i.e. whether a topic is repeated or not, becomes more random and less predictable than it actually is. Hence, we believe that our estimates for the percentage of susceptible users and for the gains of the topic repeat probability due to community feedback are both lower bounds.
Third, we only looked at one type of behavior, topic continuation vs. topic change, and looked at effects averaged across all topics. Other behaviors, such as time until the next post or even churn probabilities could be looked at. Furthermore, the effect might be heterogeneous across topics. Future work is needed to look at different types of behavior change, as well as additional factors that might influence the effect heterogeneity.
Fourth, our current study does not look at who provides feedback, whether a close friend, an acquaintance, or a stranger. Previous work looking at fact-checking interventions for false statements on Twitter [29, 47] found that the type of social link did effect the likelihood to accept a fact-checking intervention. While the collection of social network information adds certain technical challenges related to API limits, the incorporation of such information seems a promising future direction.
Fifth, an additional, inherent challenge when collected data from online platforms is the fact that these platforms change for at least two reason: (i) Their user bases changes and, once no longer undergoing exponential growth, generally matures both in terms of expertise on the platform as well as in terms of biological age. (ii) Platforms periodically introduce new features, such as Twitter’s “retweet with comment” [21] or its expansion of the 140 character limit to 280 [24]. In a sense, every new feature creates a new platform, making before-after generalizations difficult. While our method is expected to be applicable to future versions of the platforms studied, the quantitative findings might not be.
Sixth, our approach for estimating treatment effect based on predictive modeling may be affected by model misspecification. We assume the logistic model and identify the confounding variables by exploring possible factors for the author’s posting behavior. Although the high prediction accuracy (82% for Reddit and Twitter) suggests that our predictive model is reasonable, there are many possible choices for the model and it is likely that more predictive models will be developed in future. For instance, it is interesting to extend the proposed model by incorporating the history of posting behavior of a user. Additionally, similar to the matching methods, our method might miss confounding variables, which may affect the estimate of the community feedback effect. For example, our model neglects the temporal information, i.e., the time of previous posting. It would be interesting to develop such a predictive based on point process [37]. Our method can control some of unobserved confounders by including the global topic trend in the model. Specifically, we adopted a simple random walk model for the topic trend \(g_{k}(t)\), having a property of autoregressive smoothness. We note that this model could be extended to incorporate seasonality and rapid changes [35].
Finally, it is possible that social feedback affects emotions more than observable actions such as topic choice. For example, Marayuma et al. [48] observe that “receiving positive feedback to social media posts instills a psychological sense of community in the poster.” However, they do not report any actual behavior change. Reasoning about internal, mental states using social media is inherently challenging and something that this work does not attempt to do.
7.2 Broader impact
Our results contribute to the discussion on how operant conditioning affects social media users [1, 15] and suggest that social feedback systems are a critical and sensitive part of social media platforms that has an agenda-setting effect. The results of this study have implications for the design of social media. Prior studies show that social feedback influences opinions of consumers about online content and its propensity to spread [26, 55], whereas this study shows its impact on authors’ decisions on the topic to post next. We note that polarizing or biased topics receive more feedback than impartial topics [73]. One can hypothesize that social influence contributes to this effect, by boosting the spread of topics that arouse emotions and elicit quick positive feedback from susceptible users. A potential solution addressing this issue is a novel design of social rating systems that accounts for susceptibilities of users.
Finally, we note that topic choice is a higher-level cognitive task [50], related to free will, so it is surprising that it is influenced by social feedback, although the father of operant conditioning considered free will an illusion [62, 65]. It remains an open question how many of our choices are determined by various kinds of feedback, including social feedback, and how many are the result of free will.
Notes
We explored other time intervals and found qualitatively the same results.
References
Andreassen CS (2015) Online social network site addiction: a comprehensive review. Curr Addic Rep 2(2):175–184
Aral S, Walker D (2012) Identifying influential and susceptible members of social networks. Science 337:337–341
Arganda S, Pérez-Escudero A, de Polavieja GG (2012) A common rule for decision making in animal collectives across species. Proc Natl Acad Sci USA 109(50):20508–20513
Bernstein MS, Bakshy E, Burke M, Karrer B (2013) Quantifying the invisible audience in social networks. In: CHI, pp 21–30
Bhattacharya R, Nabi R, Shpitser I (2020) Semiparametric inference for causal effects in graphical models with hidden variables. arXiv:2003.12659
Bishop CM (2006) Pattern recognition and machine learning. Springer, New York
Boyd S, Boyd SP, Vandenberghe L (2004) Convex optimization. Cambridge University Press, Cambridge
Cheng J, Adamic L, Dow PA, Kleinberg JM, Leskovec J (2014) Can cascades be predicted? In: WWW, pp 925–936
Cheng J, Danescu-Niculescu-Mizil C, Leskovec J (2014) How community feedback shapes user behavior. In: ICWSM, pp 61–70
Choromanska A, Henaff M, Mathieu M, Arous GB, LeCun Y (2015) The loss surfaces of multilayer networks. J Mach Learn Res 38:192–204
Cohen J (2013) Statistical power analysis for the behavioral sciences. Academic Press, San Diego
Conway BA, Kenski K, Wang D (2015) The rise of Twitter in the political campaign: searching for intermedia agenda-setting effects in the presidential primary. J Comput-Mediat Commun 20(4):363–380
Crane R, Sornette D (2008) Robust dynamic classes revealed by measuring the response function of a social system. Proc Natl Acad Sci 105(41):15649–15653
Cunha T, Weber I, Pappa G (2017) A warm welcome matters!: the link between social feedback and weight loss in/R/loseit. In: WWW, pp 1063–1072
Deibert RJ (2019) The road to digital unfreedom: three painful truths about social media. J Democr 30(1):25–39
Eckles D, Kizilcec RF, Bakshy E (2016) Estimating peer effects in networks with peer encouragement designs. Proc Natl Acad Sci 113(27):7316–7322
Forster M, Sober E (1994) How to tell when simpler, more unified, or less ad hoc theories will provide more accurate predictions. Br J Philos Sci 45:1–35
French M, Bazarova NN (2017) Is anybody out there? Understanding masspersonal communication through expectations for response across social media platforms. J Comput-Mediat Commun 22(6):303–319
Fujita K, Medvedev A, Koyama S, Lambiotte R, Shinomoto S (2018) Identifying exogenous and endogenous activity in social media. Phys Rev E 98(5):052304
Gaffney D, Matias JN (2018) Caveat emptor, computational social science: large-scale missing data in a widely-published reddit corpus. PLoS ONE 13(7):1–13.
Garimella K, Weber I, De Choudhury M (2016) Quote rts on Twitter: usage of the new feature for political discourse. In: WebSci, pp 200–204
Gelman A, Hwang J, Vehtari A (2014) Understanding predictive information criteria for Bayesian models. Stat Comput 24(6):997–1016
Ghosh S, Sharma N, Benevenuto F, Ganguly N, Cognos KG (2012) Crowdsourcing search for topic experts in microblogs. In: SIGIR, pp 575–590
Gligoric K, Anderson A, West R (2018) How constraints affect content: the case of Twitter’s switch from 140 to 280 characters. In: ICWSM, pp 596–599
Grabowicz P, Babaei M, Kulshrestha J, Weber I (2016) The road to popularity: the dilution of growing audience on Twitter. In: ICWSM, pp 567–570
Grabowicz PA, Romero-Ferrero F, Lins T, de Polavieja GG, Benevenuto F, Gummadi KP (2015) An experimental study of opinion influenceability. arXiv:1802.02163
Grinberg N, Dow PA, Adamic LA, Naaman M (2016) Changes in engagement before and after posting to Facebook. In: CHI, pp 564–574
Grinberg N, Kalyanaraman S, Adamic LA, Naaman M (2017) Understanding feedback expectations on Facebook. In: CSCW, pp 726–739
Hannak A, Margolin D, Keegan B, Weber I (2014) Get back! You don’t know me like that: the social mediation of fact checking interventions in Twitter conversations. In: ICWSM
Hirano K, Imbens GW (2005) The propensity score with continuous treatments. In: Appl. Bayesian model. Causal inference from IncompleteData perspect. Wiley, New York, pp 73–84.
Hoyer PO, Janzing D, Mooij JM, Peters J, Schölkopf B (2009) Nonlinear causal discovery with additive noise models. In: NIPS, pp 689–696
Hutto CJ, Vader EG (2014) A parsimonious rule-based model for sentiment analysis of social media text. In: ICWSM
Imai K, Van Dyk DA (2004) Causal inference with general treatment regimes: generalizing the propensity score. J Am Stat Assoc 99(467):854–866
Kiciman E, Counts S, Gasser M (2018) Using longitudinal social media analysis to understand the effects of early college alcohol use. In: ICWSM, pp 171–180
Kitagawa G, Gersch W (1996) Smoothness priors analysis of time series. Springer, Berlin
Kobayashi R, Kurita S, Kurth A, Kitano K, Mizuseki K, Diesmann M, Richmond BJ, Shinomoto S (2019) Reconstructing neuronal circuitry from parallel spike trains. Nat Commun 10(1):1–13
Kobayashi R, Tideh RL (2016) Time-dependent Hawkes process for predicting retweet dynamics. In: ICWSM, pp 191–200
Kobayashi R, Tsubo Y, Lansky P, Shinomoto S (2011) Estimating time-varying input signals and ion channel states from a single voltage trace of a neuron. In: NIPS, pp 217–225
Kramer ADI, Guillory JE, Hancock JT (2014) Experimental evidence of massive-scale emotional contagion through social networks. Proc Natl Acad Sci 111(24):8788–8790
Küçük D, Can F (2020) Stance detection: a survey. ACM Comput Surv 53(1):12
Latane B (1981) The psychology of social impact. Am Psychol 36(4):343–356
Latané B, L’Herrou T (1996) Spatial clustering in the conformity game: dynamic social impact in electronic groups. J Pers Soc Psychol 70(6):1218
Lee D, Kim HS, Kim JK (2011) The impact of online brand community type on consumer’s community engagement behaviors: consumer-created vs. marketer-created online brand community in online social-networking web sites. Cyberpsychol Behav Soc Netw 14(1–2):59–63
Lehmann J, Gonçalves B, Ramasco JJ, Cattuto C (2012) Dynamical classes of collective attention in Twitter. In: WWW, pp 251–260
Lipton ZC (2018) The mythos of model interpretability. Commun ACM 61(10):36–43
Litt E (2012) Knock, knock. Who’s there? The imagined audience. J Broadcast Electron Media 56(3):330–345
Margolin DB, Hannak A, Weber I (2018) Political fact-checking on Twitter: when do corrections have an effect? Polit Commun 35(2):196–219
Maruyama M, Robertson SP, Douglas S, Raine R, Semaan B (2017) Social watching a civic broadcast: understanding the effects of positive feedback and other users opinions. In: CSCW, p 794807
Marwick AE, Boyd D (2011) I tweet honestly, I tweet passionately: Twitter users, context collapse, and the imagined audience. New Media Soc 13(1):114–133
Maslow AH (1943) A theory of human motivation. Psychol Rev 50(4):370–396
Matthews BW (1975) Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochim Biophys Acta, Protein Struct 405(2):442–451
McCombs ME, Shaw DL (1972) The agenda-setting funcion of mass-media. Public Opin Q 36:176–187
McCorriston J, Jurgens D, Ruths D (2015) Organizations are users too: characterizing and detecting the presence of organizations on Twitter. In: ICWSM, pp 650–653
Metaxas P, Mustafaraj E, Wong K, Zeng L, O’Keefe M, Finn S (2015) What do retweets indicate? Results from user survey and meta-review of research. In: ICWSM, pp 658–661
Muchnik L, Aral S, Taylor SJ (2013) Social influence bias: a randomized experiment. Science 341(6146):647–651
Naylor RW, Lamberton CP, West PM (2012) Beyond the like button: the impact of mere virtual presence on brand evaluations and purchase intentions in social media settings. J Mark 76(6):105–120
Olteanu A, Varol O, Kiciman E (2017) Distilling the outcomes of personal experiences: a propensity-scored analysis of social media. In: CSCW, pp 370–386
Pearl J (2009) Causality: models, reasoning and inference, 2nd edn. Cambridge University Press, Cambridge
Perez-Vega R, Waite K, O’Gorman K (2016) Social impact theory: an examination of how immediacy operates as an influence upon social media interaction in Facebook fan pages. Mark Rev 16(3):299–321
Rubin DB (1974) Estimating causal effects of treatments in randomized and nonrandomized studies. J Educ Psychol 66(5):688–701
Russell S, Norvig P (2010) Artificial intelligence: a modern approach. Prentice Hall, Imprint of Pearson Education, Upper Saddle River
Schacter DL, Gilbert DT, Wegner DM (2011) Psychology, 2nd edn. Worth, New York
Scissors L, Burke M, Wengrovitz S (2016) What’s in a like?: attitudes and behaviors around receiving likes on Facebook. In: CSCW, pp 1501–1510
Shimizu S, Hoyer PO, Hyvärinen A, Kerminen A (2006) A linear non-Gaussian acyclic model for causal discovery. J Mach Learn Res 7:2003–2030
Skinner BF (1938) The behavior of organisms: an experimental analysis. Appleton-Century, Oxford.
Spirtes P, Zhang K (2016) Causal discovery and inference: concepts and recent methodological advances. Appl Inf 3(1):3
Stuart EA (2010) Matching methods for causal inference: a review and a look forward. Stat Sci 25(1):1–21
Trilling D (2015) Two different debates? Investigating the relationship between a political debate on TV and simultaneous comments on Twitter. Soc Sci Comput Rev 33(3):259–276
Wager S, Athey S (2018) Estimation and inference of heterogeneous treatment effects using random forests. J Am Stat Assoc 113(523):1228–1242
Xu Z, Zhang Y, Wu Y, Yang Q (2012) Modeling user posting behavior on social media. In: SIGIR, pp 545–554
Yang Z, Guo J, Cai K, Tang J, Li J, Zhang L, Su Z (2010) Understanding retweeting behaviors in social networks. In: CIKM, pp 1633–1636
Yin H, Cui B, Chen L, Hu Z, Huang Z (2014) A temporal context-aware model for user behavior modeling in social media systems. In: SIGMOD, pp 1543–1554
Zafar MB, Gummadi KP, Danescu-Niculescu-Mizil C (2016) Message impartiality in social media discussions. In: ICWSM, pp 466–475
Zhang Q, Gong Y, Guo Y, Huang X (2015) Retweet behavior prediction using hierarchical Dirichlet process. In: AAAI, pp 403–409
Zhao WX, Jiang J, Weng J, He J, Lim E-P, Yan H, Li X (2011) Comparing Twitter and traditional media using topic models. In: ECIR, pp 338–349
Availability of data and materials
The Reddit data used in this analysis can be freely downloaded from pushshift.io.Footnote 5 The Twitter can also be crawled and used according to Twitter policy on data sharing
Funding
Kobayashi acknowledges support from the following sources: JSPS KAKENHI (grants JP17H03279, JP18K11560, and JP19H01133), JST ACT- I (grant JPMJPR16UC), and JST PRESTO (grant JPMJPR1925). Grabowicz acknowledges support from Volkswagen Foundation (grant 92136).
Author information
Authors and Affiliations
Contributions
PAG, RK and IW conceptualized the study; RK, PAG, and DIA devised the methodology; PAG collected the data; DIA developed the software, performed the simulations and analyzed the data; RK, PAG and IW wrote the manuscript with input from all authors. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
David Ifeoluwa Adelani and Ryota Kobayashi contributed equally to this work.
Appendices
Appendix
Appendix A: Up/down-votes and likes as feedback
In the main text, the feedback amount is calculated based on the number of comments or retweets. Since we have the timestamps for these individual pieces of feedback, we count only the feedback that was received before the next post is created, because only this feedback can causally influence the topic of the next post. Here, we calculate the feedback amount based on the difference in the number of up-votes and down-votes on Reddit and the number of likes on Twitter. We examine the distribution of susceptibility among the users (Table 6). The new results are quantitatively similar to the results of the main text (Table 5). It should be noted that the new results might be less causally valid since we do not have the timestamps of votes and likes.
Appendix B: Effect of topic granularity on Twitter results
We investigate whether the number of topics, K, impacts our results and conclusions. First, we examine the effect of topic granularity on prediction accuracy. When the number of topics is increased from 100 to 200, the accuracy slightly improves except for all the models: the accuracy is \(70.56 \pm 0.00\)%, \(74.90 \pm 0.01\)%, \(80.82 \pm 0.00\)%, \(81.21 \pm 0.00\)%, and \(83.27 \pm 0.17\)% for the five models specified in Table 4. Second, we examine the effect of topic granularity on the distribution of the susceptibility \(\alpha _{i}\). With increased granularity the number of positive, negative, and insignificant users changes to 12%, 3%, and 85%, respectively (compare with Table 5). Overall, the results do not change qualitatively when we change the topic granularity on Twitter.
Appendix C: Detailed analysis of the prediction performance of the proposed model
We evaluate the performance of the proposed model (Eq. (1)) in predicting the topic change of a user. The proposed model considers three types of features: the user-dependent propensity to continue any topic (“Prop”), the preference to topics (“Pref”), and the topic trend due to news and social events (“Trend”). The prediction performance was evaluated by three metrics: the accuracy (“ACC”), the F1 score (“F1”), and the Matthews correlation coefficient (“MCC”) [36, 51], defined as
where TP, TN, FP, and FN is the number of true positives, true negatives, false positives, and false negatives, respectively, and the positive class corresponds to topic continuation. Tables 7 and 8 show the prediction performance for Reddit and Twitter, respectively. The results are qualitatively the same for the three measures. The topic preference of a user is a much more important feature than the propensity to topic continuation, and the topic trend further improves the prediction accuracy.
Appendix D: Similarity between the topic trend and the popularity of posts
The topic trend \(g_{k}(t)\) describes the effect of the topic on the probability of topic continuation in a subsequent post. Figures 5 and 6 show the comparison between the topic trend and the number of post per day on a given topic in Reddit and Twitter, respectively. Whereas the topic trend is similar to the popularity of the posts, they are different because the topic trend is defined as a logit of the probability and it is smoothed.

A comparison between the topic trend \(g_{k}(t)\) (blue in the left panels) and the popularity of posts (black in the right panels) over time in Reddit. The gray area represents the 95% confidence interval of the topic trend. Filled circles mark the days when the topic trend is significantly higher than zero for at least three consecutive days. The three examples are the same as those in Fig. 3

A comparison between the topic trend \(g_{k}(t)\) (green in the left panels) and the popularity of posts (black in the right panels) over time in Twitter. The gray area represents the 95% confidence interval of the topic trend. Filled circles mark the days when the topic trend is significantly higher than zero for at least three consecutive days. The three examples are the same as those in Fig. 3
Appendix E: Comparison of the prediction performance among the feedback functions
To determine the feedback function, we compare the prediction performance of three feedback functions f (Eq. (1)): (i) the feedback quantity x, (ii) its logarithm \(\log (x)\), and (iii) its probability integral transform \(P( X_{i}< x)\), where \(P(X_{i} < x)\) is the probability that the given ith user receives feedback smaller than x. We examined two feedback quantities x: (a) the feedback amount \(n_{i}\), where \(n_{i}\) is the number of comments (Reddit) or retweets (Twitter) from the previous post, and (b) the feedback rate \(n_{i}/\Delta t\), where Δt is the duration from the previous post. Table 9 and 10 show the prediction accuracy based on the feedback amount and rate, respectively. Feedback rate improves the prediction accuracy in comparison to feedback amount. We adopt the cumulative probability of the feedback rate, \(P(R_{i}< r_{i})\), as the feedback function, because it achieves the best accuracy.
Appendix F: Dependency of the distribution of susceptibility on posting activity
In the main text, we focused on the expert users who post actively, that is, they post more than 50 posts in six months. We examine the dependency of the distribution of the susceptibility (Table 5) on the posting rate. The users in Reddit and Twitter were divided into four groups (G1, G2, G3, and G4) based on the number of posts, each group having the same sample size. The number of posts by the users in G1 ranges from 50 to Q1, where Q1 is the first quartile of the number of posts. The number of posts by the users in G2 ranges from Q1 to Q2, where Q2 is the second quartile of the number of posts. In the same way, the number of posts by the users in G3 ranges from Q2 to Q3, and the number of posts by the users in G4 is above Q3. The quartiles of the number of posts were 71, 92, and 139 in Reddit, and 133, 281, and 666 in Twitter. Then, we compared the susceptibility distribution among the four groups. In Reddit, the fraction of users who are positively influenced drops with increasing posting rate (Table 11), suggesting that more active users tend to be less susceptible. In Twitter, this fraction increases with the posting rate (Table 12).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Adelani, D.I., Kobayashi, R., Weber, I. et al. Estimating community feedback effect on topic choice in social media with predictive modeling. EPJ Data Sci. 9, 25 (2020). https://doi.org/10.1140/epjds/s13688-020-00243-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjds/s13688-020-00243-w