- Regular article
- Open access
- Published:
Prestige drives epistemic inequality in the diffusion of scientific ideas
EPJ Data Science volume 7, Article number: 40 (2018)
Abstract
The spread of ideas in the scientific community is often viewed as a competition, in which good ideas spread further because of greater intrinsic fitness, and publication venue and citation counts correlate with importance and impact. However, relatively little is known about how structural factors influence the spread of ideas, and specifically how where an idea originates might influence how it spreads. Here, we investigate the role of faculty hiring networks, which embody the set of researcher transitions from doctoral to faculty institutions, in shaping the spread of ideas in computer science, and the importance of where in the network an idea originates. We consider comprehensive data on the hiring events of 5032 faculty at all 205 Ph.D.-granting departments of computer science in the U.S. and Canada, and on the timing and titles of 200,476 associated publications. Analyzing five popular research topics, we show empirically that faculty hiring can and does facilitate the spread of ideas in science. Having established such a mechanism, we then analyze its potential consequences using epidemic models to simulate the generic spread of research ideas and quantify the impact of where an idea originates on its longterm diffusion across the network. We find that research from prestigious institutions spreads more quickly and completely than work of similar quality originating from less prestigious institutions. Our analyses establish the theoretical trade-offs between university prestige and the quality of ideas necessary for efficient circulation. Our results establish faculty hiring as an underlying mechanism that drives the persistent epistemic advantage observed for elite institutions, and provide a theoretical lower bound for the impact of structural inequality in shaping the spread of ideas in science.
1 Introduction
A core principle of scientific progress is the free exchange of ideas, which enables the best ideas to spread throughout the scientific community. But, some ideas spread further than others, and these differences create a kind of epistemic inequality [44], in which some researchers and institutions are far more influential than others. These observed inequalities may reflect the impact of genuine differences in merit, or the importance of non-meritocratic factors associated with whom or where an idea originated, or both. Past studies of scholarly productivity show dramatic epistemic inequality: scientists at elite institutions produce the majority of research articles [44], play an outsized role in setting the pace and direction of scientific achievement [2, 14, 33, 42], and receive the majority of both professional awards and recognition [3, 12, 27, 28, 45].
Such differences alone, however, are not clear evidence that epistemic inequality is driven by non-meritocratic social mechanisms, and there are very few data-driven tests for such mechanisms. As a result, it remains unknown how the spread of an idea may depend on where it originated in the scientific community. Moreover, if the point of origination does shape its fate within scientific discourse, what is the relationship between the idea’s intrinsic fitness and the structural advantage afforded by the prestige of the origin? Progress on these questions would shed new light on systematic inequalities in scientific discourse and inform efforts to mitigate structural impediments to scientific progress. We also note that academia represents a kind of model system for studying socially-mediated information diffusion, as publications and institutions create a rich data ecosystem. As a result, insights on the spread of ideas in science may also yield new insights into other information diffusion settings, such as online social environments [5, 8, 40].
Past work on non-meritocratic factors that influence the spread of ideas in science has focused on two categories: institutional prestige and researcher prestige. Elite departments are known to provide resources that facilitate high rates of productivity and innovation [18, 37], including research funding, departmental staff, quality graduate students, and advanced facilities. Access to such resources can attract intrinsically talented researchers and foster environments that may naturally produce better ideas [21, 25, 26, 38].
Similarly, researcher influence itself can follow a cumulative advantage dynamic, called the “Matthew Effect” in science, in which productivity and notoriety facilitate greater subsequent productivity and notoriety. As a result, well-known scientists tend to receive more credit than lesser-known scientists for work of comparable quality [27]. Furthermore, faculty in prestigious departments tend to be more visible to the research community [13, 43], which can facilitate the spread of their ideas [1, 11, 34]. This greater visibility is often attributed to higher publication rates, greater representation in elite publication venues [39], and greater engagement in informal scientific communication, e.g., circulating manuscripts and face-to-face communication [21].
Here, we take a different approach, focusing instead on characterizing how faculty hiring drives epistemic inequality by determining which researchers are located at which institutions, and hence what ideas originate where. Faculty hiring can act as a transmission mechanism for the spread of research ideas, because researchers carry ideas that have been reinforced during their doctoral studies [35] to their faculty institution [9]. In this way, if a department becomes newly active in a particular research topic, it must have either hired as faculty a researcher who already works on that topic, or one of its existing faculty changed their research interests to align with the topic (e.g. via many other possible mechanisms such as conferences, social media, etc.). Hence, graduates who train under these faculty, who themselves go on to take faculty positions at still other institutions, and students of those faculty, etc., represent the continued spread of the idea, via faculty hiring alone, throughout the scientific community. From a historical perspective, the adoption of Feynman diagrams via the hiring of a small group of post-doctoral researchers from a single institution, represents an example of this mechanism [24, 36].
To test the hypothesis that research ideas can spread to new universities through faculty hiring, we begin by analyzing the timing and topics of 200,476 computer science publications, and the hiring dates of 2583 associated faculty. Having found evidence to support this hypothesis, we then use comprehensive data on 5032 faculty hires at the 205 Ph.D.-granting departments of computer science in the U.S. and Canada to construct a faculty hiring network that embodies the conduits along which ideas may flow among institutions. Using numerical simulations of simple epidemic models on this network, we quantify the impact on how far ideas of different inherent quality spread as a function of different originating institutions within the network. We find that ideas originating from prestigious universities spread faster and more completely than ideas from less prestigious universities, and we extract a generic “exchange rate” function that quantifies the tradeoff between increasing university prestige and decreasing quality of a research idea for generating an epidemic of a particular size.
The concept of a “research idea” can span a diverse set of definitions, ranging from the development of a pioneering analysis technique or algorithm to the novel synthesis of previously disjoint observations. In Sect. 3, we evaluate hiring as one possible mechanism for the spread of ideas by identifying particular research topics via keywords in publication titles. For modeling purposes, in Sect. 4 we adopt a purposefully abstract definition of a “research idea” as a meme with some intrinsic quality represented by the probability of transmission between two connected institutions. Accordingly, we consider the spreading of ideas at the level of institutions, where the adoption of an idea by a department is signaled by having at least one faculty member who’s published research on that topic. This construction is amenable to most reasonable concepts of a research idea and sheds light on the implicit tradeoffs between idea quality, network position, and the extent to which it spreads through the scientific community.
2 Hiring and publication data
Our study employs two comprehensive and complementary data sets. One contains detailed education and employment histories of faculty at Ph.D.-granting computer science (CS) departments in the U.S. and Canada, along with data-driven estimates of each institution’s “prestige.” The other contains the set of publications written by individual faculty who are listed in the first data set. Below we describe each in detail.
2.1 Faculty hiring network
We utilize an existing hand-collected data set of 5032 tenured or tenure-track faculty from the set of all 205 Ph.D.-granting computer science departments in the U.S. and Canada [9]. From these data, we construct a multi-edge, directed faculty hiring network in which nodes represent universities, and an edge \((u, v)\) exists if a person received their Ph.D. from university u and held a tenure-track position at university v during the 2011–2012 academic year. Universities may have many edges between them, representing multiple researchers trained at u who took a position at v. This network also contains self-loops, corresponding to individuals who received their Ph.D. at the same institution at which they hold a faculty position. We have omitted all non-Ph.D.-granting universities from our analysis, as well as faculty who received their Ph.D. from out-of-sample institutions.
2.2 Departmental prestige
Each institution in the data set is annotated by a data-driven estimate of its “prestige” within the faculty hiring system [9], and we use this covariate to structure our investigation of how ideas spread differently depending on where the originate. Here, prestige measures a department’s ability to place its graduates as faculty at other institutions, which has been shown to correlate with other departmental rankings (e.g., those compiled by U.S. News & World Report and the National Research Council), but more accurately predicts faculty placement [9].
Past research on visibility in science suggests that several institutional characteristics contribute to the success of individual researchers, in particular department size and prestige [1, 13]. Size is considered an “almost necessary” condition for excellence [21] among academic departments, which require a minimum number of faculty in order to achieve sufficient breadth in research. However, other studies find that department size is only a weak predictor of success [7, 25] or has diminishing effect [17, 23] on the research output of faculty.
In contrast, departmental prestige is consistently an excellent predictor of faculty placement outcomes [9, 41], and hiring a graduate of u as faculty at v can be viewed as a kind of implicit endorsement of the perceived quality of u. Prestige also tends to correlate with department size and output [42], but also allows small departments to have high placement power, or large departments to have low power. In addition to prestige, we also considered how other network-derived department characteristics correlated with spreading power, including eigenvector, in-degree (department size), out-degree (number of placed faculty), and closeness centrality scores. Of these, departmental prestige correlated most strongly, and hence we focus our investigation on how departmental prestige shapes the dissemination of research ideas.
Departmental prestige represents a node-level attribute extracted from the faculty hiring network, which is defined as a directed multigraph \(G = (V, E)\), with \(|V|=N\) nodes. A prestige hierarchy is defined as a mapping \(\pi: V \to[1,N]\), where \(\pi_{i}\) is the prestige of node i, by convention \(\pi_{i}=1\) is the highest prestige possible, and the number of “rank violations” is minimized. A rank violation is simply some edge \((u,v)\in E\) where the prestige of v exceeds the prestige of u, i.e., the edge points “up” the hierarchy. In practice, however, there are many rankings π with the same fraction of rank violations, and the prestige variable we use is the average prestige rank \(\langle\pi_{i}\rangle \) over all minimum violation rankings [9].
There are three features of the CS faculty hiring network that are relevant for our study. First, the prestige hierarchy is steep, with only 12% of CS faculty placing at institutions more prestigious than their doctorate. Second, it has a pronounced core-periphery structure [9], in which prestige correlates with how “close” in the network a department is to other departments, as measured by the mean geodesic distance (Fig. 1). Third, there is enormous inequality in faculty production, and the number of placed faculty (out-degree) correlates with department prestige (Fig. 2). This inequality is sufficiently extreme that only 18 (of 205) departments account for the doctorates of 50% of all CS faculty in our data set [9]. Hence, in a practical sense, prestige drives faculty hiring.

Average length \(\langle\ell\rangle\) of a geodesic path originating from a university with prestige π, in the strongly connected component of the computer science faculty hiring network, showing a strong linear correlation between a node’s “closeness” centrality and its prestige

Coarsened adjacency matrix of the computer science faculty hiring network, sorted by prestige and aggregated into 10 groups. Shading is proportional to the density of edges between a pair of prestige deciles, and the strong upper triangle pattern indicates a strong prestige hierarchy
2.3 Faculty publications
We also utilize an existing data set of papers authored by a subset of CS faculty listed in the faculty hiring network data set [41]. These data enable an empirical test of the mechanistic hypothesis that faculty hiring drives the spread of research ideas. Validating this mechanism provides the theoretical basis for our subsequent simulation-based investigation.
In-sample faculty for this data set are those from the faculty hiring network for whom both the doctoral department is known and the department of the first assistant professor appointment is known, which is the primary transition for faculty hiring. For these faculty, publication records were obtained by manually linking faculty profiles to publication records on DBLP [16], an online database spanning major computer science journals and conference proceedings. The result is a list of the timing and titles of 200,476 publications by 2583 professors, which has previously been shown to be a representative sample [41, 42].
3 Faculty hiring and epistemic inequality
The strong core-periphery structure of the faculty hiring network implies that, in terms of spreading dynamics, elite institutions have a structural advantage. However, investigating the consequences of this structure is only meaningful if scientific ideas can and do spread by way of faculty hiring. In this section, we construct a simple test to evaluate whether faculty hiring is a mechanism that shapes the spread of ideas in the academic computer science community. This test can be carried out for any research area with a well defined and specific set of associated terminology, and which is widely adopted across the community. Here, we apply the test to five well-known areas that satisfy these criteria: (i) “deep learning,” (ii) “topic modeling,” (iii) “incremental computation,” (iv) “quantum computing,” and (v) “mechanism design.”
For each topic, a list of 7–56 keywords was generated manually for us by a set of at least two experts working within the corresponding field. Using the DBLP publication data for our in-sample CS faculty, we then extracted the associated set of publications for a topic using simple keyword matching on publication titles, with a manual verification step to guarantee each paper’s topical relevance, yielding 1116, 217, 71, 167, and 122 publications respectively. Searching for words in titles will likely result in an under-classification of publications relevant to a research topic. For the measures of ideas transmitted via faculty hiring considered below, since we require that relevant research is carried out at their institution before and after their hiring, it is possible that we have classified events which should have been labeled as a transmission due to hiring as not. Given this approach, our measurement of research adoption via hiring is likely a conservative estimate or lower bound on the true number of such events.
Finally, for each faculty member j at each department i, we construct an indicator time series \(f_{i,j}(t)=1\) if faculty j published an on-topic paper in year t, and \(f_{i,j}(t)=0\) if they did not. We then mark this time series with the year \(t^{*}_{j}\) in which j was hired into the department.
For each department i, there are three scenarios for whether and how a topic X spreads to i:
-
1.
(Null) X never spreads to department i, and hence for each faculty j at department i, \(f_{i,j}=0\).
-
2.
(Hiring) X spreads to i (or, i “adopts” X) by the hiring of new faculty j who has previously published on X (Fig. 3(A)), i.e., a “transmission” of X from one department to another, carried by the new faculty j. In this case, no faculty at i has published on X prior to the \(t^{*}_{j}\), faculty j has published on X prior to \(t^{*}_{j}+2\), and j publishes on X subsequently. The choice of allowing j’s “prior” work on X to occur up to 2 years after their faculty hiring event captures the fact that work carried out before being hired can take several years to be formally published.
Figure 3 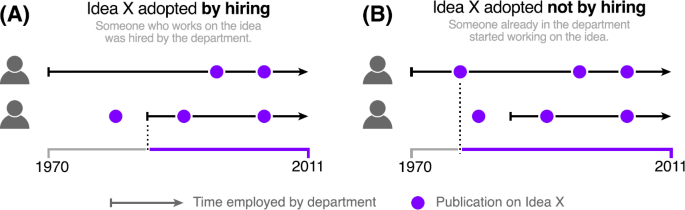
If an idea X spreads to a department, the first person to work on X must either be (A) a newly hired faculty with prior work on X (hiring adoption), or (B) an existing faculty without prior work on X (non-hiring adoption). Black lines depict a faculty’s time at a university, and purple dots signify relevant (on topic) publications
-
3.
(Non-hiring) X spreads to i by one of their existing faculty publishing on X for the first time (Fig. 3(B)). In this case, some faculty j at i publishes on X prior to the hiring of any new faculty who have previously worked on X, without themselves representing scenario 2.

Inspecting the time series of hiring events at all 205 universities, we recover a total of 241 spreading events for the five topics, each affecting between 11% and 58% of departments. Of these events, 88 (37%) are due to transmissions of research ideas by way of hiring, and in 81% of these cases, transmissions move via faculty from higher prestige universities to lower prestige universities (past studies show that only 9 to 14% of faculty placements move faculty to a more prestigious university than their doctoral institution [9]). Figure 4 illustrates these patterns by showing spreading events over time, for three of the topics.

Adoption events for the three research topics over time. Purple dots denote institutions who adopted an idea by hiring someone who studies that topic, and white dots represent institutions whose existing faculty began working on the topic. Arrows denote, for each time period, new transmissions, originating from the hired individual’s doctoral location. All 205 institutions are arranged clockwise by prestige (descending), with the most prestigious department positioned at noon
Crucially, if faculty hiring shapes the spread of ideas, then a significant share of departments that ever adopt a topic X will have adopted it through faculty hiring (scenario 2). We test this hypothesis by constructing a specialized permutation test to assess the statistical significance of the empirically observed fraction of departments that have adopted a research idea via scenario 2, denoted \(f_{\mathrm{obs}}\), and the expected fraction of such departments \(f_{\mathrm{exp}}\). The test’s null model is one in which the publication years for each faculty are fixed with their empirical values, but paper titles are drawn uniformly at random, without replacement, from the set of all titles. In this way, serial correlations in topics and temporal correlations with the hiring event are removed from each faculty. We then report empirical p-values [30] for the fraction of hiring-driven adoption events for each topic.
For all five research topics, the observed fraction of adoptions by hiring \(f_{\mathrm{obs}}\) exceeds the expected fraction \(f_{\mathrm{exp}}\) under the null model. However, the observed fraction was only statistically significant in four of five topics, topic modeling, incremental computing, quantum computing and mechanism design, while no significant difference was found for deep learning (Table 1).
These results indicate that faculty hiring appears to act as a mechanism for the spread of ideas, with differential effects by topic, across the computer science community. Faculty hiring has mostly clearly shaped the spread of topic modeling and incremental computing, and the lack of significance for deep learning is interesting. As previously discussed, this null result could be spurious, as the sampled nature of our data make it likely that we have underestimated the true share of departments that adopted a topic by hiring. However, it could also be related to the broad popularity of and interest in deep learning itself, which led to many more adoption events that were not driven by hiring. This case highlights the fact that faculty hiring may not play a statistically significant role in the spread of every research idea. At the same time, the other cases indicate that hiring does play a statistically significant role in others. The sample of research topics analyzed here should by no means be considered exhaustive, and, as such, we make no claims about the extent to which all research ideas spread via this mechanism. Instead, our results here establish that faculty hiring is a possible mechanism for the diffusion of ideas in academia, and we welcome future research to further explain which ideas spread by hiring and why.
4 Prestige and the diffusion of ideas
Having established empirically that faculty hiring itself plays a role in shaping the spread of real ideas across the scientific community, we now investigate the aggregate, system-level consequences of faculty hiring, and the links it creates between departments, on the spread of ideas, using numerical simulations. Our first model assumes faculty hiring is the sole mechanism by which research ideas spread throughout academia, and then we relax this assumption by allowing for diffusion via other mechanisms. This approach allows us to characterize how where an idea originates, and in particular the prestige of the originating department, shapes how broadly an idea may spread through faculty hiring, as a function of the idea’s intrinsic quality. Hence, we quantify the degree to which ideas originating from more prestigious universities may spread more broadly than equally good ideas from less prestigious universities.
4.1 Modeling the spread of ideas
We model the spread of an idea across the CS faculty hiring network using a simple network model of information diffusion. Formally, this model is equivalent to an SI model in network epidemiology, repurposed here to model the spread of a meme [32].
In this model, nodes are in either a “susceptible” (S) or an “infected” (I) state; all nodes begin in state S; and, only the \(S\to I\) state transition is allowed (no remission from infections). In the sense of ideas spreading, a department that adopts an idea (scenario 2 or 3 in Sect. 3) undergoes the \(S\to I\) transition. If some node u undergoes the \(S\to I\) transition, then in the next time step of the simulation, each of its susceptible neighbors independently undergoes the \(S\to I\) transition with probability p, where the chance for transmission of an idea across an edge is only allowed once (though multiple edges can exist between institutions). This probability quantifies the intrinsic quality or transmissibility of the idea, so that higher values of p represent ideas that spread more easily. Finally, to initialize the simulation, a particular node u is selected to undergo the \(S\to I\) transition, and time then progresses until no new nodes transition to the I state. This model assumes an independence between the prestige of node u and the transmissibility of the idea p originating at that node. Additionally, more complicated epidemiological models are not considered here, but represent interesting directions for future work. For example, the SIS model allows a department to return to the S state, e.g., by losing all its faculty who publish on a given topic. This model could be used to study the ebb and flow of interest in a topic across the network.
For each department u in the hiring network, we run a large number (\(10{,}000\)) of SI simulations with u as the initial node, and we measure the mean epidemic size Y, i.e., the fraction of universities in state I when the diffusion stops, and mean epidemic length L, i.e., the number of time steps in the simulation. We then evaluate how these quantities covary with the prestige π of the originating department, and the transmissibility of the idea p.
4.2 Results
4.2.1 Simple SI model
These information diffusion simulations show that ideas that originate at more prestigious universities tend to spread farther (larger epidemic size) than those originating at less prestigious universities, for ideas of similar quality (Fig. 5).

Normalized epidemic size \(Y/N\) as a function of prestige of the originating university π. Each data point represents an average result over 1000 trials of the simulation. Colors correspond to different transmission probabilities p
This difference reveals a structural advantage that correlates with university prestige and its impact is most pronounced for lower-quality ideas. That is, lower-quality ideas (smaller p) that originate at more prestigious institutions will tend to spread farther than comparable ideas (same p) that originate at less prestigious institutions. Accordingly, increasing p has a more dramatic effect on increasing the corresponding epidemic size produced by lower prestige institutions. In other words, our simulations suggest that high-quality ideas will tend to spread throughout the network regardless of where they begin (although at different timescales, Fig. 6). But, the structural advantage of higher prestige tends to enhance the circulation of lower-quality ideas, and is likely related to the way prestige correlates with increased network centrality and more faculty alumni. Notably, these simulation results corroborate past empirical studies of the effects of prestige on researchers’ citations and visibility [11, 13].

Normalized epidemic length \(L/\ell\) as a function of prestige of the originating university π. Each data point represents an average result over 1000 trials. Each curve is colored corresponding to different transmission probabilities p and fitted using a LOWESS curve
To model the effect of prestige π on the size Y of the resulting epidemic, we fit logistic curves to the results:
where \(y_{\max }\) is the upper bound of the size, k is the growth rate, and \(\pi_{\text{mid}}\) is the symmetric inflection point. The good visual agreement between a logistic growth curve and our simulation results (Fig. 5) suggests that for a particular idea fitness p, there exists a range of prestige values within which linear increases in prestige result in exponential increases in epidemic size. For smaller values of p, this range is concentrated among the most prestigious universities, reflecting their structural advantage. As p increases, the range shifts progressively toward lower-prestige universities. In other words, for linear increases in p, we observe non-linear epidemic sizes.
We also find that prestige shapes how long ideas tend to circulate in the network, as measured by the length L of the epidemic, normalized by the average length of a geodesic path ℓ from the originating university (Fig. 6). This ratio \(L/\ell\) quantifies the degree to which an idea circulates beyond or below the shortest-path percolation. For high-quality ideas (larger p), we find that the epidemic length L tends to be similar regardless of where an idea originates, although there is a slight positive correlation with prestige. However, lower-quality ideas from higher-prestige universities circulate much longer than if they originate from lower-prestige universities, again illustrating the structural advantage that prestige affords in the diffusion of ideas when we consider faculty hiring as the only mechanism by which ideas spread.
4.2.2 SI model with jumps
We now relax the importance of faculty hiring by introducing a stochastic “jump” into the transmission model, which models the aggregate effect of other spreading mechanisms—word-of-mouth, professional meetings, reading the literature, social media, etc.
Because faculty hiring tends to be highly selective on the prestige of hiring and placing institutions [9], some universities are disconnected from large sections of the faculty hiring network. However, ideas that originate at these peripheral universities should still have some chance to spread through means other than faculty hiring or the communication conduits created by those relationships. To capture this effect, in the lifetime of an epidemic, each university u that has made the \(S\to I\) transition, in addition to its faculty hiring transmissions, will also transmit the idea to exactly one university, selected uniformly at random from u’s set of unreachable nodes, with “jump” probability q. This process mirrors the “teleportation” probability of random walkers in the PageRank algorithm [31].
This variation of our information diffusion simulation shows that increasing the likelihood of this non-hiring transmission modestly improves the spread of ideas originating from the lowest prestige universities (Fig. 7), as these universities now have some chance of transmitting an idea to a more central institution. Even very high jump probabilities, however, do not mitigate the strong structural advantage in spreading that the highest-prestige universities exhibit. Similarly, q has only a marginal impact on the epidemic size produced by the highest prestige institutions, whose ideas already tend to spread widely across the network.

Normalized epidemic size \(Y/N\) as a function of prestige of the originating university π, allowing for a single jump to a disconnected node. Transmission probability is held constant at \(p = 0.1\). Each data point represents an average over 500 trials. Colors correspond to different jump probabilities q
4.2.3 A generic tradeoff between prestige and idea fitness
Knowing that prestige exerts such a strong influence on the spread of ideas across the network, we now consider whether there exists a generic relationship between the prestige of the originating university and the quality of the idea it is spreading. In this way, we aim to quantify the tradeoff between these two variables by asking: For a given epidemic size, how much must p increase to compensate for a decrease in π?
To begin, we stratify institutions into decile groups according to their prestige. We then compute the average epidemic size \(Y/N\) among universities in each decile, as a function of transmission probability p, and fit logistic functions to these data. This analysis reveals that ideas originating from the lowest-prestige universities, even if they are of the highest quality, are unlikely to spread to the whole network (red line, Fig. 8(A)), and again reinforces the substantial structural advantage afforded to more prestigious universities. As a result, less prestigious universities face substantial structural barriers in the spread of their original ideas, independent of their quality, which may play a role in persistent epistemic inequality and the dominance of elite universities in the pace and direction of scientific progress.

(A) Normalized epidemic size \(Y/N\) as a function of transmission probability p for each university averaged across the universities in a prestige decile. (B) Epidemic sizes for normalized transmission probabilities. Each data point represents an average across all universities in a decile, and across the 1000 trials for each university, transmission probability pair
To quantify the precise relationship among prestige π, idea quality p, and epidemic size Y, we use a technique from statistical physics called a “data collapse” to extract a generic functional form. When a set of curves are parameterized special cases of a more general function, the generic function can be identified and estimated by “rescaling” the individual curves so that they collapse onto each other [29]. To obtain this function, we rescale the decile curves in Fig. 8(A) using an ansatz that relates p and d, the decile of prestige, i.e., 0.1 for the top 10% most prestigious universities, 0.2 for the next 10%, etc.:
This ansatz converts p and d into an “effective” transmission probability \(p^{*}\), and its form illustrates the exponential rescaling effect of prestige (via the decile variable d now) on the raw transmission probability p. Hence, as the prestige of the originating university decreases, in order to produce an epidemic of equivalent size, the transmission probability of the idea must increase at an exponential rate to compensate.
Replotting the epidemic size data as a function of the effective transmission probability produces the data collapse (Fig. 8(B)), and confirms the existence of a generic functional relationship, in which epidemic size varies as a function of p and d alone, via \(p^{*}\):
where r and k are constants of best fit. Under this function, a choice of prestige decile d that originates an idea and a choice of idea quality p would allow us to roughly predict the fraction of the network the idea will eventually reach.
5 Conclusion
Past studies of scholarly productivity and affiliation suggest that researchers at elite institutions play an outsized role in driving the pace and direction of scientific progress [2, 3, 12, 14, 27, 28, 33, 42, 45]. Here, using comprehensive data on faculty hiring events in the field of computer science, we investigated the consequences of a university’s prestige on the diffusion of ideas it originates. Using epidemic models to simulate the spread of ideas across the faculty hiring network, we find that ideas originating from more prestigious universities produce larger epidemic sizes and longer epidemic lengths. Consequently, ideas starting in the network periphery (i.e., at less prestigious universities) must be much higher in quality to have similar success as lower quality ideas originating in the core (more prestigious universities). These findings suggest that idea dissemination within academia is not meritocratic, even when the assessment of the idea’s quality (transmission probability p) is entirely objective.
While these results may appear intuitive, our study provides a detailed and quantitative characterization of the theoretical consequences of institutional prestige on the spread of ideas across the scientific community. These measurements build upon the notion that research ideas spread throughout academia by way of faculty hiring, either through the direct transfer of researchers working on a particular topic or by the lines of communication created between placing and hiring institutions [2, 13]. We tested the hypothesis that faculty hiring acts as a mechanism for the spread of ideas by carefully cross-inspecting DBLP publication data and faculty hiring events, showing that indeed, faculty hiring plays a statistically significant role in driving the spread of some ideas. Specifically, the spread of the research topics incremental computation, topic modeling, quantum computing, and mechanism design was significantly driven by faculty hiring events in our network. The same could not be said for deep learning, however, which may suggest that deep learning is a less specialized, possibly less well-defined, research topic. Alternatively, deep learning may simply represent a particularly high-quality idea, whose adoption was both widespread and rapid (see Fig. 4).
Our investigation of these five areas of research was limited by matching keywords to titles of publications, and for computer science faculty only. Analysis of full-text articles or abstracts would facilitate more precise detection of publications relevant to particular research areas [19]. Along these lines, a more detailed analysis of how robust the faculty hiring mechanism is under a more specific, or more broad, definition of a research area is an interesting and important direction of research. Future work should consider extending the analyses performed here to other departments where faculty hiring network data are available. Subsequently, our analyses of idea diffusion suppose that faculty hiring provides the primary conduit for the spread of research and models all other modes of diffusion using a small, uniform jump probability that connects all universities. To the extent that these other modes of diffusion are structured and can be measured, future work should consider modeling their effects directly to provide more realistic estimates of idea diffusion.
Additionally our work focuses on faculty hiring as a mechanism for the spread of ideas throughout academia. Certainly, other mechanisms exist that influence the dissemination of ideas, including those mediated by the scientific literature and its underlying citation network. Our analysis of the random jump model helps explain the transmission of ideas under transmission mechanisms independent of prestige. If we believe that many other mechanisms that drive the spread of ideas are strongly correlated with prestige, as is the case for citation networks [13, 14, 22, 28], then despite the fact that these mechanisms are different from the one we are testing, the inclusion of their effects in our analysis might only slightly mitigate the structural advantage we observe.
Our results suggest that researchers at prestigious institutions benefit substantially from a structural advantage that allows their ideas to more easily spread throughout the network of institutions, and consequentially, impact the discourse of science. This advantage presumes that ideas spread according to a purely meritocratic notion of idea quality and that ideas of high quality can originate from any institution. If it is instead the case that the quality of an idea is correlated with its origination (i.e., high quality ideas are more likely to come from prestigious institutions) then the quality of an idea would act as a confounding factor to the faculty hiring mechanism. Producing an objective, empirical measurement of an idea’s quality is difficult and would require, for example, an assertion of the relative worth of advancements in theory versus methodology, which remains an open problem. Nevertheless, past research supports the existence of a “halo effect” in science [4, 15, 27], whereby ideas are perceived as being of higher quality if they originate from prestigious institutions and researchers. As such, our results may indicate only a lower bound for the actual advantage of that elite universities enjoy. Future studies should consider modeling non-meritocratic factors such as the halo effect in addition to the purely meritocratic effects analyzed in our study.
A difficult question left unanswered by this work is what, if anything, should be done about the impact of non-meritocratic social mechanisms on epistemic inequality in scientific discourse. Our results indicate that faculty hiring is one social mechanism that drives this inequality, and past work has established that university prestige drives faculty hiring [9]. Hence, if differences in faculty placement rates across universities remain unchanged (i.e., institutions continue to hire faculty with doctorates from a small number of elite departments), then the current highly differential spread of ideas is unlikely to change on its own.
Somewhat more optimistically, our results show that while lower quality ideas will tend to be overshadowed by comparable ideas from more prestigious institutions, high quality ideas circulate widely, regardless of their origin. Epistemic inequality, then, could be mitigated by incentivizing researchers to produce a smaller number of higher quality studies over a larger number of incremental, low-quality studies. Additionally, there may be opportunities to mitigate epistemic inequality through new technologies and careful experimentation [10]. For example, the adoption of double-blind review processes [20] and the practice of posting early manuscripts online may facilitate the visibility of high quality ideas from less prestigious universities. However, these online tools may also amplify academia’s existing inequalities [6]. Continued experimentation of this form will be important for monitoring the effects of policy on epistemic inequality in science. We look forward to more work on understanding the mechanisms that create and maintain epistemic inequality, and innovative ideas to promote the free circulation of good ideas.
Abbreviations
- CS:
-
computer science
- SI:
-
susceptible-infected
- SIS:
-
susceptible-infected-susceptible
References
Aaltojärvi I, Arminen I, Auranen O, Pasanen HM (2008) Scientific productivity, Web visibility and citation patterns in sixteen Nordic sociology departments. Acta Sociol 51(1):5–22
Allison PD, Long JS (1990) Departmental effects on scientific productivity. Am Sociol Rev 55(4):469–478
Allison PD, Long JS, Krauze TK (1982) Cumulative advantage and inequality in science. Am Sociol Rev 47(5):615–625.
Astin AW, Solmon LC (1981) Are reputational ratings needed to measure quality?. Change 13(7):14–19
Bakshy E, Hofman JM, Mason WA, Watts DJ (2011) Everyone’s an influencer: quantifying influence on Twitter. In: Proc. 4th ACM intl. conf. web search and data mining, ACM, WSDM ’11, pp 65–74. https://doi.org/10.1145/1935826.1935845
Beel J, Gipp B (2009) Google Scholar’s ranking algorithm: an introductory overview. In: Proc. 12th intl. conf. scientometrics and informetrics, vol 1. Rio de Janeiro, Brazil, pp 230–241
Blackburn RT, Behymer CE, Hall DE (1978) Research note: correlates of faculty publications. Sociol Educ 51(2):132–141.
Cheng J, Adamic L, Dow PA, Kleinberg JM, Leskovec J (2014) Can cascades be predicted? In: Proc. 23rd intl. conf. World Wide Web, ACM, WWW ’14, pp 925–936. https://doi.org/10.1145/2566486.2567997
Clauset A, Arbesman S, Larremore DB (2015) Systematic inequality and hierarchy in faculty hiring networks. Sci Adv 1(1):e1400005. https://doi.org/10.1126/sciadv.1400005
Clauset A, Larremore DB, Sinatra R (2017) Data-driven predictions in the science of science. Science 355(6324):477–480
Cole S (1970) Professional standing and the reception of scientific discoveries. Am J Sociol 76(2):286–306
Cole S, Cole JR (1967) Scientific output and recognition: a study in the operation of the reward system in science. Am Sociol Rev 32(3):377–390
Cole S, Cole JR (1968) Visibility and the structural bases of awareness of scientific research. Am Sociol Rev 33(3):397–413
Crane D (1965) Scientists at major and minor universities: a study of productivity and recognition. Am Sociol Rev 30(5):699–714
Cutright M (2003) In pursuit of prestige: strategy and competition in US higher education. J High Educ 74(2):238–241
DBLP (2018) DBLP: Computer Science Bibiliography. http://dblp.uni-trier.de
Dundar H, Lewis DR (1998) Determinants of research productivity in higher education. Res High Educ 39(6):607–631
Fox MF (1983) Publication productivity among scientists: a critical review. Soc Stud Sci 13(2):285–305
Gerow A, Hu Y, Boyd-Graber J, Blei DM, Evans JA (2018) Measuring discursive influence across scholarship. Proc Natl Acad Sci. http://www.pnas.org/content/early/2018/03/09/1719792115.full.pdf. https://doi.org/10.1073/pnas.1719792115
Goues CL, Brun Y, Apel S, Berger E, Khurshid S, Smaragdakis Y (2017) Effectiveness of anonymization in double-blind review. arXiv:1709.01609
Hagstrom WO (1971) Inputs, outputs, and the prestige university science departments. Sociol Educ 44(4):375–397
Helmreich RL, Spence JT, Beane WE, Lucker GW, Matthews KA (1980) Making it in academic psychology: demographic and personality correlates of attainment. J Pers Soc Psychol 39(5):896–908
Jordan JM, Meador M, Walters SJ (1988) Effects of department size and organization on the research productivity of academic economists. Econ Educ Rev 7(2):251–255
Kaiser D (2005) Physics and Feynman’s diagrams. Am Sci 93(2):156–165
Kyvik S (1995) Are big university departments better than small ones?. Res High Educ 30(3):295–304
Long JS, McGinnis R (1981) Organizational context and scientific productivity. Am Sociol Rev 46(4):422–442
Merton RK (1968) The Matthew effect in science. Science 159(3810):56–63. https://doi.org/10.1126/science.159.3810.56
Moed HF (2006) Bibliometric rankings of World Universities. CWTS Report 1
Newman MEJ, Barkema GT (1999) Monte Carlo methods in statistical mechanics. Clarendon, Oxford
North BV, Curtis D, Sham PC (2002) A note on the calculation of empirical P values from Monte Carlo procedures. Am J Hum Genet 71(2):439–441
Page L, Brin S, Motwani R, Winograd T (1998) The PageRank Citation Ranking: Bringing Order to the Web
Pastor-Satorras R, Castellano C, Van Mieghem P, Vespignani A (2015) Epidemic processes in complex networks. Rev Mod Phys 87:925–979. https://doi.org/10.1103/RevModPhys.87.925
Pelz DC, Andrews FM (1976) Scientists in Organizations: Productive Climates for Research and Development. IMR–Ind Manag Rev
Petersen AM, Fortunato S, Pan RK, Kaski K, Penner O, Rungi A, Riccaboni M, Stanley HE, Pammolli F (2014) Reputation and impact in academic careers. Proc Natl Acad Sci USA 111(43):15316–15321
Petersen EB (2007) Negotiating academicity: postgraduate research supervision as category boundary work. Res High Educ 32(4):475–487
Rotabi R, Danescu-Niculescu-Mizil C, Kleinberg JM (2017) Tracing the use of practices through networks of collaboration. In: Proc. 11th intl. conf. Web and social media, pp 201–209
Smeby JC, Try S (2005) Departmental contexts and faculty research activity in Norway. Res High Educ 46(6):593–619
Stankovic J, Aspray W (2003) Recruitment and retention of faculty in computer science and engineering. Computing research association, USA
Van Dalen HP, Henkens K (2005) Signals in science – on the importance of signaling in gaining attention in science. Scientometrics 64(2):209–233
Watts D, Dodds P (2007) influentials, networks and public opinion formation. J Consum Res 34(4):441–458
Way SF, Larremore DB, Clauset A (2016) Gender, productivity, and prestige in computer science faculty hiring networks. In: Proc. 25th intl. conf. World Wide Web, intl. World Wide Web conferences steering committee, pp 1169–1179
Way SF, Morgan AC, Clauset A, Larremore DB (2017) The misleading narrative of the canonical faculty productivity trajectory. Proc Natl Acad Sci USA 114(44):E9216–E9223
Weingart P (2005) Impact of bibliometrics upon the science system: inadvertent consequences?. Scientometrics 62(1):117–131
Wellmon C, Piper A (2017) Publication, power, and patronage: on inequality and academic publishing. Crit Inq
Zuckerman H (1967) Nobel laureates in science: patterns of productivity, collaboration, and authorship. Am Sociol Rev 32(3):391–403
Acknowledgements
The authors thank Daniel Larremore, Chad Wellmon, Andrew Piper, Jon Kleinberg, and Bailey Fosdick for helpful conversations.
Availability of data and materials
The dataset and code supporting the conclusions of this article are available in the allisonmorgan/epistemic_inequality repository, https://github.com/allisonmorgan/epistemic_inequality.
Funding
Authors ACM, SFW, and AC were supported by National Science Foundation Award SMA 1633791. ACM was also supported by an National Science Foundation Graduate Research Fellowship Award DGE 1650115.
Author information
Authors and Affiliations
Contributions
All authors developed the research questions and designed the experiments and analyses. ACM and DJE analyzed the data and conducted the numerical experiments. ACM, DJE, and SFW prepared the figures and tables. All authors wrote the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Morgan, A.C., Economou, D.J., Way, S.F. et al. Prestige drives epistemic inequality in the diffusion of scientific ideas. EPJ Data Sci. 7, 40 (2018). https://doi.org/10.1140/epjds/s13688-018-0166-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjds/s13688-018-0166-4